大家好,今天让我们来聊聊项目技术文档。
正如我在推特上所说的,我将会在接下来的一段时间里,来分享我在过去几年里参与内部或者开源项目技术文档的时候,学到的一些有用的经验。
我绝不会说我是技术文档方面的专家,但是从个人习惯来说,我确实算是比较喜欢写文档的那类工程师。
与其说是为了说教式地描述如何写文档,不如说是兴趣使然地对这个主题的讨论。
那么言归正传,我们先来聊聊项目技术文档是什么。
从我的观察结果来说,计算机行业的项目技术文档可以分为两类:
- 手册,也就是纯粹的 Manual Book,包含了你执行
man <cmd>或者Swagger API这样列表式的指南。 - 综合文档,类似于 Kafka Docs 或者 Kubernetes Docs 这样的,同时面向用户和开发者,并且更专注于教程和概念的综合文档。
本系列的博文会着重于 综合文档 这一类,这也是大家在工作上更常见、更有概率参与维护的一类文档。在接下来的篇幅中,没有特别说明的话,技术文档这个词都会指代 综合文档。
而 手册 类的文档一般来说都已经直接包含在了项目本体的代码仓库里,结构化程度也没有那么多层。
¶我所理解的技术文档
其实很难精确定义技术文档是什么,因为 CNCF, Apache, Linux Foundation 等开源机构自身的文档可以说是各有各的思路和设计哲学。
但是如果要找出技术文档在底层框架上和其他类型的文档的区别的话,还是容易的。计算机行业的技术文档,多半具备这些特点:
- 文档应由版本控制工具进行托管的,无论是 Git 还是 Mercurial。
- 文档应具备一系列根据实际需求创建的校验和开发者工具,并且配置与之对应的 CI/CD 流程。
- 文档应具备预发布/渲染机制,例如在 Merge Request 中提供新版本的 Preview 渲染。
任何开源/商业项目的开发,抽象到最后本质都是 工程学 的一个分支。
用工程学的思维进行文档代码库的设计,并且根据实际环境进行长期的迭代和跟踪,也许就是技术文档和常规文档的最大的区别。
¶版本控制
正如标题所言,今天这篇博文我们不谈技术文档的内容怎么写,而只谈工程学上,怎么给技术文档打好地基。
技术文档区别于散文、议论文乃至于学术论文,有几个独特的点:
- 对 “精确” 的要求极高。
- 迭代速度极快。热门项目的技术文档往往有五位数甚至六位数的 PR。
- 参与人数极多。公司内部项目几十上百人参与,开源热门项目往往上千人。
这些特点决定了,如果技术文档不托管在版本控制软件中,很容易在短时间里失控(内容失控 + 管理失控)。
因为不同人的行文风格差异很大,对于热门项目来说,确保行文和用词的一致性是很困难的。
所以不可避免地,需要使用 Merge Request 或者 Pull Request 这样的机制来进行文档的审核。这样,不同分支的管理者,就可以根据开发者规范和本地化风格规范,对文档的风格进行长期的跟踪和维持。
作为案例,Kubernetes 中文文档的开发者规范就做得很不错。
在 Repository 中,大家使用 script/lsync.sh 来对上游分支(也就是英语分支)进行提交的跟踪。对于单个文档页面,只要最后一次的中文同步提交早于最后一次的英语上游提交,便是做没有完成上游同步。
举个例子,当页面 Ingress 控制器的上游英语版本发生了改变以后,文档贡献者就可以非常轻易地发现更新内容,根据中文本地化样式指南的规范,修改并且提交 PR 来确保下游简中分支的同步:
$ scripts/lsync.sh content/zh-cn/docs/concepts/services-networking/ingress-controllers.md
diff --git a/content/en/docs/concepts/services-networking/ingress-controllers.md b/content/en/docs/concepts/services-networking/ingress-controllers.md
index 7391839f85..fc19265b39 100644
--- a/content/en/docs/concepts/services-networking/ingress-controllers.md
+++ b/content/en/docs/concepts/services-networking/ingress-controllers.md
@@ -41,6 +41,7 @@ Kubernetes as a project supports and maintains [AWS](https://github.com/kubernet
* [Easegress IngressController](https://github.com/megaease/easegress/blob/main/doc/reference/ingresscontroller.md) is an [Easegress](https://megaease.com/easegress/) based API gateway that can run as an ingress controller.
* F5 BIG-IP [Container Ingress Services for Kubernetes](https://clouddocs.f5.com/containers/latest/userguide/kubernetes/)
lets you use an Ingress to configure F5 BIG-IP virtual servers.
+* [FortiADC Ingress Controller](https://docs.fortinet.com/document/fortiadc/7.0.0/fortiadc-ingress-controller-1-0/742835/fortiadc-ingress-controller-overview) support the Kubernetes Ingress resources and allows you to manage FortiADC objects from Kubernetes
* [Gloo](https://gloo.solo.io) is an open-source ingress controller based on [Envoy](https://www.envoyproxy.io),
which offers API gateway functionality.
* [HAProxy Ingress](https://haproxy-ingress.github.io/) is an ingress controller for
.....类似的好处其实远不止在本地化的过程中。
当面对多个版本或者 Tag 的文档的管理的时候,文档的 Owner 可以非常灵活地编辑不同版本和 Tag 的管理员和审核者名单,并且保证不同分支之间内容的共享和隔离,能够被精确记录。
当尝试接入 CI/CD 流程来确保审核的流畅性,以及支持页面预渲染和预发布的时候,利用版本控制软件,也可以更好地引入 GitLab CI, GitHub Action 和 Jenkins 等特性或功能。
更进一步,我们可以导入独立的测试和流程 Repository,来模块化你的文档开发流程,并提升 CI 流程的可读性。
¶辅助工具和 CI/CD
辅助工具,指的是文档编写者用于初始化、编写、校验、测试的脚本或者可执行库。
之所以和 CI/CD 放在一起,是因为在 PR 管理和 CI/CD 流程中,这些工具往往是不可或缺的。
有时候辅助工具和 CI/CD 存在互相平替换的关系。例如 verify_spelling.sh 这样的拼写检测脚本,往往可以被 super-linter 来替代,或者协同使用。
我们很难用一个统一的框架来告诉文档设计者如何制作这些辅助工具,正如开头所说,不同的文档设计哲学,让每一个技术文档都有自身独特的流程需求和测试用例,而不同的前端框架也会让文档有完全不同的 build 环境和依赖。
但是我认为存在一些通用的技术文档工具/脚本的设计原则:
- 需要有机制跟踪提交记录的变化,如果存在多个分支或者 Tag,能够检测上下游的同步状态。
- 需要有机制检测拼写和格式的正误。
- 提供完全本地的 Build,Deployment 和验证工具。
这么说有点抽象,大家可以参考下面两个具体的案例:
- Docker Documentation 下的
*.sh脚本 - K8s Documentation Scripts
拥有这些工具之后,贡献者可以非常舒服的在本地进行文档的编写和测试,从而显著提高 Merge Request / Pull Request 的质量。
这对于文档的迭代效率和代码审核者的心智负担,都是非常有好处的。
到这里开始,我们就可以考虑为文档接入 CI/CD 流程了。考虑到多数热门项目的技术文档,都是基于现代的前端框架,这方面的流程大家都比较熟悉了。显然不需要我过多文字介绍。
举个例子,如果你的文档是用 Hugo 来构建的,那么可以很容易利用 Netlify 和 GitHub Pages 来进行自动化构建和部署:
---
name: Scheduled Netlify site build
on:
schedule:
- cron: '4 0,12 * * *'
permissions: {}
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Trigger build on Netlify
env:
TOKEN: ${{ secrets.NETLIFY_BUILD_HOOK_KEY }}
run: >-
curl -s -H "Accept: application/json" -H "Content-Type: application/json" -X POST -d "{}" "https://api.netlify.com/build_hooks/${TOKEN}"这样你就安心将文档的构建和发布交付给自动化的 Pipeline,而只需要关注于内容本身了。
¶预发布
在软件开发和发布的过程中,我们经常提到 “金丝雀发布” 这个概念。
事实上在技术文档,尤其是开源项目的技术文档的发布过程中,预发布(金丝雀)发布也很重要。
我们很容易忽视这个事情的严重性:假如一个新的 PR 在合并后,立刻反映到了线上的文档中,而这个 PR 包含了在 Review 的时候未发现的事实错误和样式渲染错误,导致读者因为这些错误,严重误解了项目部分特性的使用方式,乃至进一步造成了严重的线上事故,那就非常糟糕了。
所以,我比价推荐在 MR / PR 被创建之后,执行一次预发布,将文档部署到一个预发布环境中。
这个环境可以是一个基于容器镜像的环境,也可以是一个基于静态网站的环境。
当你为企业内部的项目工作时,这快预发布可以做的非常随意。
而当你为开源项目工作时,可以尝试 Azure DevOps,Cloudflare Pages 或者 Netlify 这样的付费服务。它们可以为你的预发布环境提供非常便捷的公共访问入口,从而让多人协作和审核变得特别简单。
如图所示,在向 Kubernetes Docs 创建新的 Pull Request 时,CI Bot 会自动为这个 PR 创建一个预发布环境,从而让 Reviewer 可以在预发布环境中查看文档的变化。
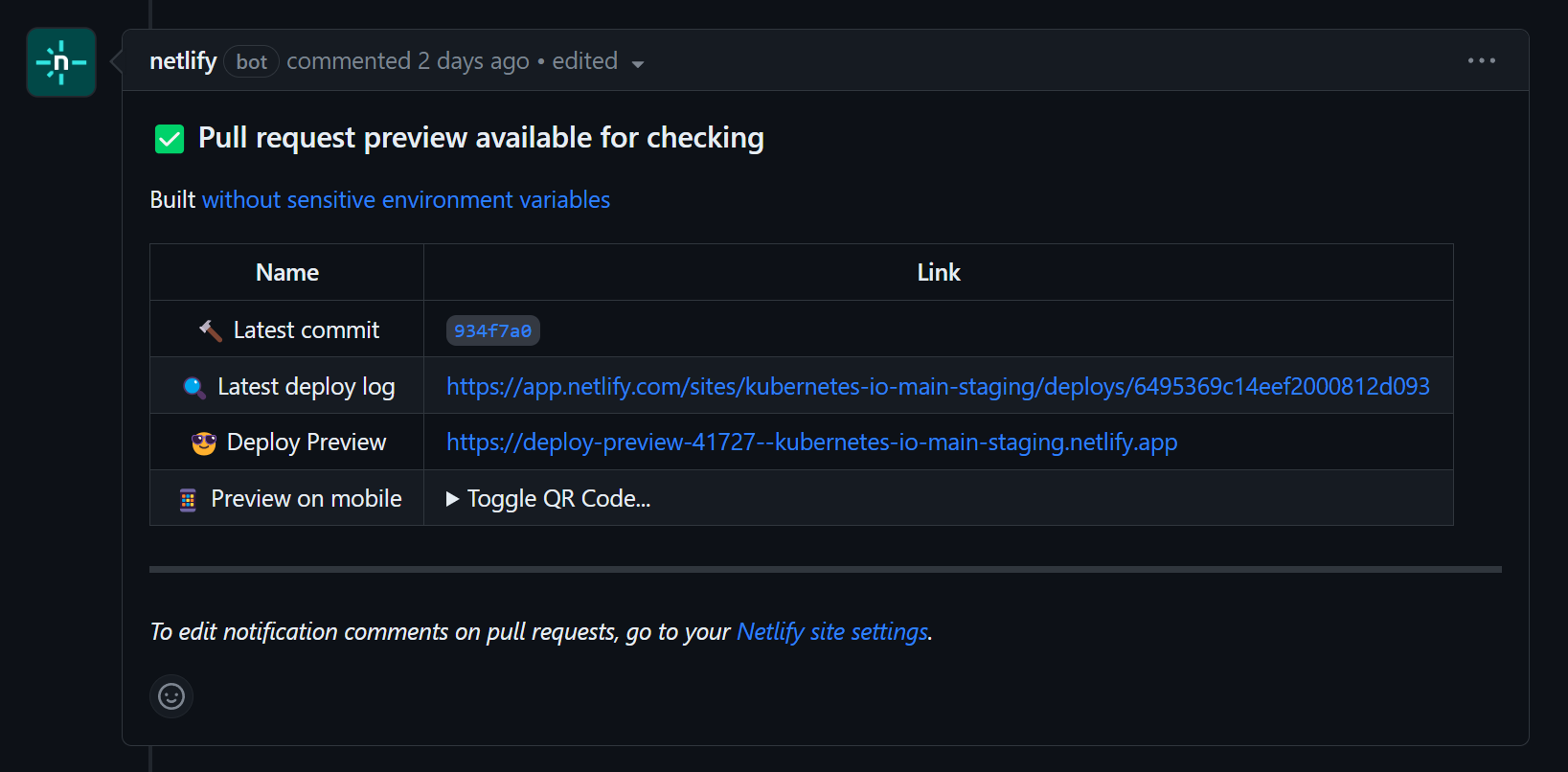
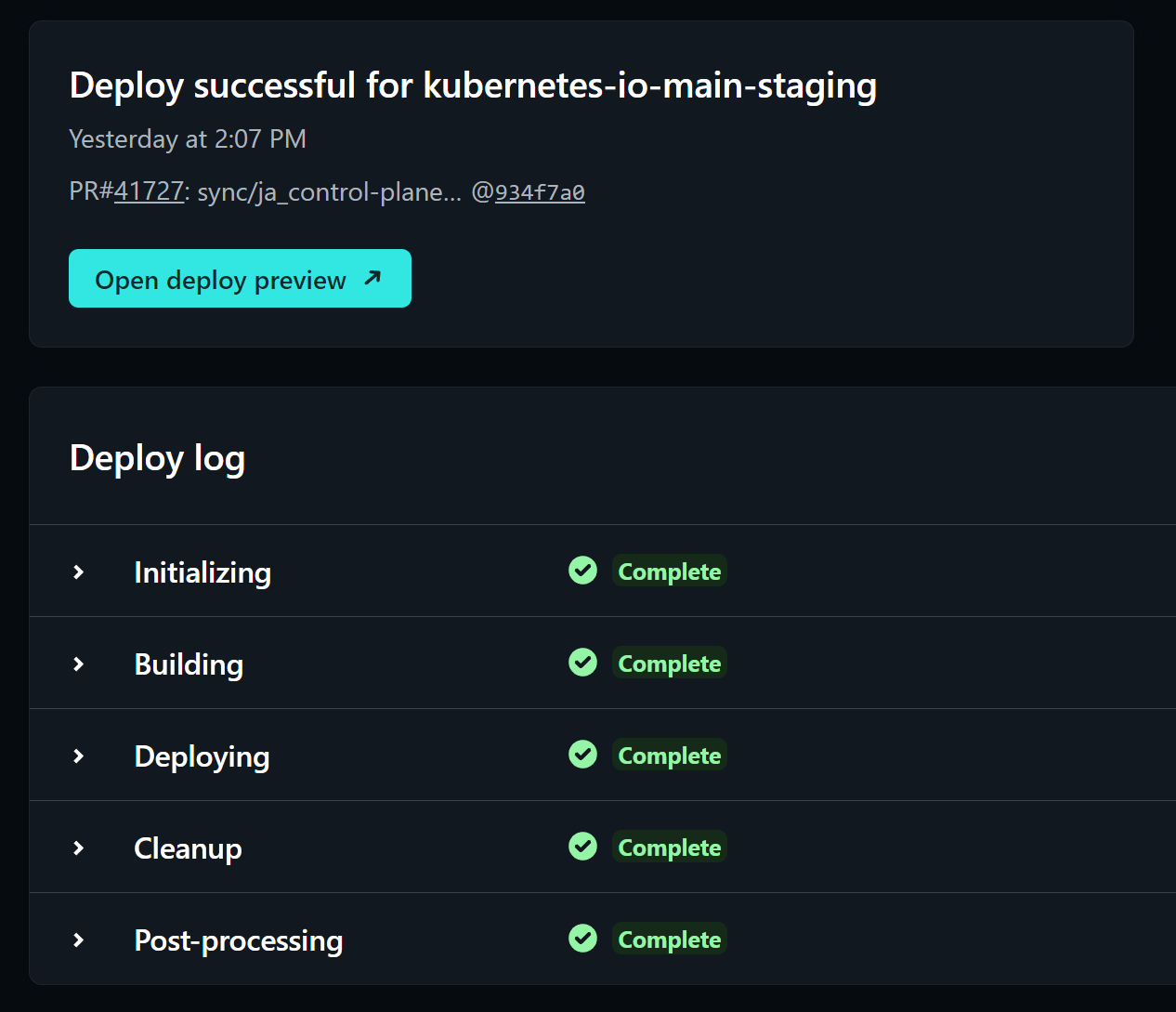
点击查看详细内容,可以看到 Netlify 执行了完整的预设流程,Build 了整个技术文章站点,并且在和 PR Number 绑定的 URI 下创建了公开的访问地址。
体验非常舒服。
¶结语
版本控制,CI/CD 流程和预发布被引入的初衷,其实是 “这么做会更好”。
更何况像 Confluence 这种广泛用于内部技术文档的平台,反而版本控制的支持一言难尽。即便提供了还不错的 Scroll Version 功能,也远说不上是特别工程化的设计逻辑。毕竟 Confluence 的用户也不完全是工程师。
引申开来,这里还有一个潜在的点值得思考。
我们聊了那么多关于文档工程化和代码库化的讨论,目的是使文档更易于长期维护和跟踪,从而提高内容的质量。
从第一性原理来说,技术文档的内容,是评判技术文档好坏的唯一标准。
切勿在追求工程化的过程中买椟还珠。事实上很多人,包括我自己,都犯过这个错误。
认真书写的 *.TXT 远好过结构精致内容空洞的工程化技术文档。这点和大家共勉。
下一篇,我会和大家聊聊有关 Convention,也就是文档规范的话题。
感谢阅读,祝大家身体健康。